From 2014-2015, I was a Database Kernel Engineer in the Distributed Systems team at MongoDB. The team was responsible for designing and implementing protocols for executing database queries on data that is distributed across multiple machines. The query plan was automatically decided based on several factors (including read/write throughput, data locality, and data distribution).
A shard key (i.e., a single indexed field or multiple fields) was used to distribute data into multiple chunks on different servers. Thus, the choice of a shard key could lead to different data distributions. This choice is especially important throughout the lifetime of executing different queries on the same data. As a result, domain knowledge of the data distribution and the lifetime of possible queries could be important in the query plan execution. In specific scientific fields (e.g., quantum physics), the data generated can be stored in a flat view. But this view does not take advantage of the data generating process to eliminate redundancies, thus resulting in costly materializations. What if we had a way to design query and storage plans using knowledge of the scientific domain? Clearly, this could lead to significant improvements in storage and computation costs.
Computational Science (or Scientific Computing) is an emerging discipline that essentially uses computers to simulate or solve scientific problems (whether in social sciences or natural sciences). The input of domain knowledge is critical to computational science. Database Theory has been crucial to the design and use of database management systems, providing the SQL (Structured Query Language) interface, the relational model and calculus, and related abstractions[1]. It is now well-acknowledged that the database management system that should be adopted depends on the type of data that would be stored and the resulting queries that can be run across the data. For example, graph database systems are well-suited for storing lots of data that represents relationships (edges) between entities (nodes). Relationships are considered first-class citizens in graph databases and so the queries are optimized for inference on graphs. Usually, the storage and indexing format implicitly takes advantage of domain knowledge of graphs for the design of the database. Can we apply a similar methodology to the design of database abstractions for scientific modeling? I assert that we can!

Task-Based Search for Alignment
Within the database community, there have been a couple of theoretical ideas and implementations that design task-based dataset search systems. The idea is as follows: given a set of providers that can provide a data corpus, the dataset search system identifies augmentable datasets that maximize the utility of a machine-learning or data-analytic task. Then these datasets are used to perform a specific analysis task. For optimization purposes, designing the search system requires domain knowledge about the query or set of queries to be performed and about other critical concerns (e.g., privacy and security). Within the artificial intelligence community that focuses on large language models, this is called AI alignment, the “process of encoding human values and goals into large language models to make them as helpful, safe, and reliable as possible. Through alignment, enterprises can tailor AI models to follow their business rules and policies”[2]. For task-based dataset search, the search systems are tailored to follow business rules and policies (with certain costs, of course) for a specific data-analytic task. However, with AI alignment, the goal is to align the system with certain values and goals without specifying a clear objective function! To train such systems, you need an evaluator (i.e., another LLM or a human being) that is able to expertly determine the effectiveness of the current LLM. The expertise of evaluator is crucial to the whole process and thus the evaluator must provide high-quality data through, for example, a task-based dataset search system! Throughout the whole process of alignment, access to high-quality data and domain knowledge is important. One could say that we need computational alignment of sciences (with domain knowledge of the data generating process) and the system where the data will be stored and queried.
Database Theory for Science Tasks
We need new theory to show the limits and capabilities of domain knowledge and task-based search for the computational sciences. Then relying on such theory, we can design more effective systems for simulating, illuminating, or solving scientific problems. To give a specific problem: the quantum many-body physics subfield concerns exploring physical properties of many interacting quantum particles. The interactions between the particles has information that is encoded in some wave function of the entire complex system. Storing and accounting for all interactions becomes infeasible quickly as the dimension of the system scales exponentially with the number of particles. Is there a way to take advantage of database approximations when performing such complex simulations?
References
[1] Raghu Ramakrishnan and Johannes Gehrke. 2002. Database Management Systems (3 ed.). McGraw-Hill, Inc., USA.
[2] IBM Research. What is AI alignment? https://research.ibm.com/blog/what-is-alignment-ai

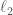 metric but it scales to other objectives as well). This has implications for improving data quality (e..g, perhaps one can identify the right augmentations that will lead to better outcomes) and heterogenous collaboration of all kinds. We evaluate our algorithms on over 300 datasets and compare to leading alternative mechanisms.
metric but it scales to other objectives as well). This has implications for improving data quality (e..g, perhaps one can identify the right augmentations that will lead to better outcomes) and heterogenous collaboration of all kinds. We evaluate our algorithms on over 300 datasets and compare to leading alternative mechanisms.